Input data
The input dataset is specified by the ‘‘obs_data’’ argument which should contain: ‘‘id’’ specifying the individual identifier, ‘‘time_name’’ specifying the time index, ‘‘covnames’’ specifying the names of time-varying covariates, ‘‘outcome_name’’ specifying the name of the outcome of interest, ‘‘compevent_name’’ indicating the competing event status (if present), ‘‘censor_name’’ indicating the censoring event status (if present).
The related arguments:
Arguments |
Description |
|---|---|
obs_data |
(Required) A data frame containing the observed data. |
id |
(Required) A string specifying the name of the id variable in obs_data. |
time_name |
(Required) A string specifying the name of the time variable in obs_data. |
outcome_name |
(Required) A string specifying the name of the outcome variable in obs_data. |
covnames |
(Required) A list of strings specifying the names of the time-varying covariates in obs_data. |
compevent_name |
(Optional) A string specifying the name of the competing event variable in obs_data. Only applicable for survival outcomes. |
censor_name |
(Optional) A string specifying the name of the censoring variable in obs_data. Only applicable when using inverse probability weights to estimate the natural course means / risk from the observed data. |
time_points |
(Optional) An integer indicating the number of time points to simulate. It is set equal to the maximum number of records (K) that obs_data contains for any individual plus 1, if not specified by users. |
The input data should contain one record for each follow-up time k for each subject (identified by the individual identifier). The time index k for each subject should increment by 1 for each subsequent interval (the starting index is 0 in the following examples, pre-baseline times are also allowed). The record at each line in the data corresponds to an interval k, which contains the covariate measurements at interval k and the outcome measurement at interval k+1.
Here is an example of input data structure for one subject which contains 7 records on the measurements of three time-varying covariates ‘‘L1’’, ‘‘L2’’, ‘‘A’’, one baseline covariate ‘‘L3’’ and the outcome ‘‘Y’’. See “example_data_basicdata_nocomp” for complete example data.

Censoring events. When there are censoring events, and users want to compute nature course estimate via inverse probability weighting, there should be a variable in the input data set that is an indicator of censoring in the time between covariate measurements in interval k and interval k+1. 1 indicates the subject is censored (C_k+1 = 1) and 0 indicates the subject is not censored (C_k+1 = 0). Subjects have no more records after they are censored. Note that the censoring indicator is not needed if users don’t want to compute the natural course estimate using IPW.
For survival outcome, the outcome Y_k+1 on the line where individual is censored (C_k+1 = 1) can be coded NA or 0. This choice will make no difference to estimates in the algorithm when intervals are made small enough such that there are no failures in intervals where there are censoring events. It depends on whether to count such subjects in the time k risk set or not [1] , [2]. For fixed binary/continuous end of follow-up, the outcome Y_k+1 should be coded NA.
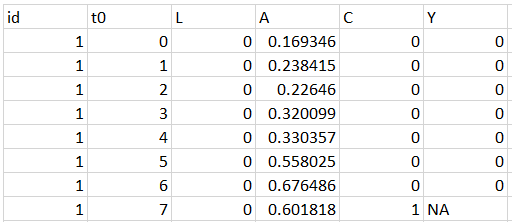
Here is an example of input data structure with a censoring event (identified by ‘‘C’’). The subject contains 8 records on the measurements of two time-varying covariates ‘‘L’’, ‘‘A’’, the outcome ‘‘Y’’ and is censored at time index k+1=8. See “example_data_censor” for complete example data.
Competing events. When there are competing events in the data, if the user chooses to treat competing events as censoring events, the data should be structured as censoring case above. If competing events are not treated as censoring events, there should be a variable in the input data set that is an indicator of competing event between interval k and k+1 covariate measurements, where 1 indicates there is a competing event for the subject (D_k+1 = 1) and 0 indicates no competing event (D_k+1 = 0). If D_k+1 = 1 on a record line k for a given subject, that subject will only have k+1 lines in the follow-up data with follow-up time k on the last line, and on that line, Y_k+1 should be coded NA. Note that the competing case is only applicable for survival outcome.
Here is an example of input data structure with a competing event (identified by ‘‘D’’). The subject contains 7 records on three time-varying covariates ‘‘L1’’, ‘‘L2’’, ‘‘A’’, one baseline covariate ‘‘L3’’ and the outcome ‘‘Y’’. The subject experiences a competing event after measurement of interval k=6 covariates. See “example_data_basicdata” for complete example data.

Note that the ‘‘time_points’’ argument specifies the desired end of follow-up (a follow-up interval k that is no more than the maximum number of records for an individual in the dataset), and is only applicable for survival outcome.